 VOYO
VOYO

 RON
RON RON
RON RON
RON RON
RON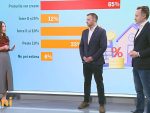 (P) iBani. Piața imobiliară după majorarea TVA. Sfaturi pentru cei interesați să cumpere o locuință nouă
(P) iBani. Piața imobiliară după majorarea TVA. Sfaturi pentru cei interesați să cumpere o locuință nouă
 ”Incont”, site-ul Știrile Pro TV de informații economice și educație financiară, a devenit ”iBani”
”Incont”, site-ul Știrile Pro TV de informații economice și educație financiară, a devenit ”iBani”  România, departe de zona euro. Analist: Probabil ne ducem spre 2030 cu adoptarea monedei unice
România, departe de zona euro. Analist: Probabil ne ducem spre 2030 cu adoptarea monedei unice
 Popa, CFA România: Într-o lume fără pensii private ar trebui să ne aşteptăm la o pensie de 32% din ultimul salariu
Popa, CFA România: Într-o lume fără pensii private ar trebui să ne aşteptăm la o pensie de 32% din ultimul salariu
 Siemens Energy anunţă concedieri masive pentru a-şi majora profitul. Compania are mii de angajați în România
Siemens Energy anunţă concedieri masive pentru a-şi majora profitul. Compania are mii de angajați în România
 Cu trenul de la Paris la Viena sau de la Zurich la Barcelona. Pandemia reînvie cursele feroviare de noapte în Europa
Cu trenul de la Paris la Viena sau de la Zurich la Barcelona. Pandemia reînvie cursele feroviare de noapte în Europa  (P) De ce aleg românii să joace la pariuri
(P) De ce aleg românii să joace la pariuri
 (P) Tot ce trebuie să știi despre vigneta Ungaria și prețul acesteia
(P) Tot ce trebuie să știi despre vigneta Ungaria și prețul acesteia
 Digitalizarea departamentului HR - un subiect în trend chiar și pentru companiile de IT
Digitalizarea departamentului HR - un subiect în trend chiar și pentru companiile de IT
 Huawei dezminte zvonurile privind vânzarea brandurilor premium de smartphone P şi Mate
Huawei dezminte zvonurile privind vânzarea brandurilor premium de smartphone P şi Mate  Cum vom lucra în 2021: 60% dintre companii vor să reînceapă munca de la birou din luna martie. Mai mult de jumătate au tăiat programele de training şi pe cele de wellbeing
Cum vom lucra în 2021: 60% dintre companii vor să reînceapă munca de la birou din luna martie. Mai mult de jumătate au tăiat programele de training şi pe cele de wellbeing  Două treimi din forţa de muncă existentă la nivel global lucrează de acasă, însă unul din trei angajaţi folosește propriul calculator pentru a-şi desfăşura activitatea
Două treimi din forţa de muncă existentă la nivel global lucrează de acasă, însă unul din trei angajaţi folosește propriul calculator pentru a-şi desfăşura activitatea Fata nestiuta a internetului. Ce se ascunde in spatele site-urilor pe care navigam zilnic si care reprezinta sub 1% din www

Ceea ce toti cunoastem sub denumirea de internet nu este decat un termen superficial. In spatele a ceea ce stim este un “ocean” de informatii si de site-uri denumite generic “Deep Web”, scrie CNN Money.
Dupa cum era de asteptat, dimensiunea reala a acestei parti a internetului este dificil de calculat. Cercetatori de la universitati de renume spun ca ceea ce cunoastem – Facebook, Wikipedia, site-urile de stiri, reprezinta mai putin de 1% din totalitatea www-ului (World Wide Web).
Internetul pe care navigam zilnic nu este decat la suprafata. Ingropate in adancurile retelei sunt zeci de trilioane de pagini – acesta este un numar estimativ, pe care majotitatea oamenilor nu le-au vazut niciodata, de la statistici plictisitoare, la site-uri pe care se vand ilegal organe.
Desi “Deep Web” este putin cunoscut, conceptul este relativ simplu. Pentru a oferi rezultatele pe care fiecare dintre noi le cauta pe internet, Google, Yahoo! sau Bing, de la Microsoft, indexeaza constant pagini. Motoarele de cautare fac acest lucru folosind linkurile dintre site-uri, creand astfel un sistem asemenator unei panze de paianjen (de unde si denumirea). Insa acestea nu pot capta decat paginile statice, ca cele obisnuite pe care intram in fiecare zi. Ceea ce nu pot capta motoarele de cautare sunt paginile dinamice, cum ar fi cele care contin baze de date.
“Atunci cand un motor de cautare ajunge la o baza de date, nu poate urmari linkurile in profunzime, dincolo de caseta de cautare”, a declarat Nigel Hamilton, fondatorul Turbo10, un motor de cautare destinat tocmai cercetarii “Deep Web”-ului, care acum nu mai functioneaza.
Astfel, Google si alte motoare de cautare nu capteaza paginile din spatele retelelor private sau al asa numitelor “pagini de site statatoare” (standalone), care nu se conecteaza la nimic. Toate acestea fac parte din “Deep Web”.
Majoritatea paginilor care alcatuiesc “Deep Web”-ul contin informatii valoroase. Un raport din 2001 estima ca mai mult de jumatate dintre site-urile de pe internet sunt baze de date, printre cele mai mari regasindu-se cel al Administratiei Nationale Oceanice si Atmosferice a SUA, cel al NASA sau cel pentru patente si marci. Toate acestea sunt publice.
Un alt nivel al “Deep Web”-ului este format din paginile private, pe care companiile le tin secrete si pentru care incaseaza bani pentru a putea fi consultate, cum ar fi cele de documente guvernamentale LexisNexis si Westlaw sau jurnalele academice de pe Elsevier.
Alte 13% dintre pagini sunt ascunse pentru ca pot fi consultate doar prin intemediul retelelor de intranet. Aceste retele cu circuit inchis – ca de exemplu cele ale universitatilor, pot fi consulatte doar de cei care fac parte din ele.
Exista apoi Tor, coltul cel mai intunecat al internetului, o colectie de site-uri secrete, care se termina in “onion” si pentru accesarea carora este nevoie de softuri speciale. Cei care folosesc Tor vor ca activitatea lor pe internet sa nu poata fi urmarita.
Tor a fost infiintat in 2002, sub denumirea The Onion Routing Project, de catre Laboratorul de cercetare navala a SUA, folosit ca metoda de comunicare online anonima. In prezent, unii il folosesc pentru comunicatii secrete, dar a devenit si un hub unde se vand droguri, se sparg conturi bancare, se face pornografie ilegala si piraterie. Prin intermediul Tor se pot angaja chiar si asasini platiti.
In timp ce “Deep Web” ramane ascuns pentru cei mai multi dintre noi, scos la lumina, valoarea sa poate fi imensa. Un motor de cautare care ar putea sa “sape” in aceasta parte intunecata a internetului ar putea furniza date importante pentru cercetare sau despre finantarile guvernamentale.
Universitatea Stanford, de exemplu, a construit un prototip de motor numit Hidden Web Exposer (HiWE), pentru a cauta in profunzime. Alte astfel de motoare accesibile publicului sunt Infoplease, PubMed sau Infomine, al Universitatii California.
 autor: iBani,
16 martie 2014 11:19
autor: iBani,
16 martie 2014 11:19
Pe acelasi subiect:
 Invață să ții sub control cheltuielile de sărbători. Cum funcționează cardul de cumpărături
Invață să ții sub control cheltuielile de sărbători. Cum funcționează cardul de cumpărături  Moneda euro la 20 de ani. Cea mai importantă realizare macro-economică a secolului trecut a supraviețuit marii crize mondiale, dar rămâne un colos handicapat de propriile slăbiciuni
Moneda euro la 20 de ani. Cea mai importantă realizare macro-economică a secolului trecut a supraviețuit marii crize mondiale, dar rămâne un colos handicapat de propriile slăbiciuni
 UE pregătește măsuri de urgență, în cazul unui ”no deal” cu Londra, din ianuarie. Domeniile vizate: pescuitul şi transportul rutier şi aerian
UE pregătește măsuri de urgență, în cazul unui ”no deal” cu Londra, din ianuarie. Domeniile vizate: pescuitul şi transportul rutier şi aerian
 Explozie la gazoductul din Ucraina care asigura gazele pentru Europa. Ce se întâmplă cu livrările de gaze rusești spre continent
Explozie la gazoductul din Ucraina care asigura gazele pentru Europa. Ce se întâmplă cu livrările de gaze rusești spre continent



 RSS
RSS